![]()
A fast and reliable flow engine for orchestration and more uses in Node.js, Deno and the browser.



![]()
Installation
npm i flowed
Browser
From public CDN
<script src="https://cdn.jsdelivr.net/npm/flowed@latest/dist/lib/flowed.js" charset="utf-8"></script>
Or replace latest in the URL for your desired version.
From package
<script src="./dist/lib/flowed.js" charset="utf-8"></script>
Getting Started
Main Features
- Parallel execution
- Dependency management
- Asynchronous and synchronous tasks
- JSON based flows
- Parametrized running
- Scoped visibility for tasks
- Run flows from string, object, file or URL
- Pause/Resume and Stop/Reset functions
- Inline parameters transformation
- Cyclic flows
- Library with reusable frequently used tasks
- Plugin system
- Debugging
Parallel execution
In order to run tasks in parallel, you don’t have to do anything. Simply adding them to a flow, they will run in parallel, of course if they don’t have dependence on each other.
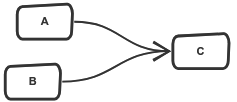
const flow = {
tasks: {
A: {
provides: ['resultA'],
resolver: {
name: 'flowed::Noop',
},
},
B: {
provides: ['resultB'],
resolver: {
name: 'flowed::Noop',
},
},
C: {
requires: ['resultA', 'resultB'],
resolver: {
name: 'flowed::Noop',
},
},
},
}
FlowManager.run(flow);
Dependency management
Only specifying dependent inputs and outputs the flow manages dependencies automatically, executing in the correct order, maximizing parallelism, and at the same time waiting for expected results when required. Note that you can specify dependence between tasks arbitrarily, not only when one of them needs results from the other.

const flow = {
tasks: {
A: {
provides: ['resultA'],
resolver: {
name: 'flowed::Noop',
},
},
B: {
requires: ['resultA'],
provides: ['resultB'],
resolver: {
name: 'flowed::Noop',
},
},
C: {
requires: ['resultB'],
resolver: {
name: 'flowed::Noop',
},
},
},
}
FlowManager.run(flow);
Asynchronous and synchronous tasks
Each task in a flow is associated to a “resolver”, which is the piece of code that runs when the task executes. So, resolvers resolve the goals of tasks. Well, those resolvers can be synchronous (simply returning its results) or asynchronous (returning a promise). The flow will take care of promises, waiting for results according to dependencies.
JSON based flow specifications
The flow specifications are written in JSON format, which means:
- They are easily serialized/unserialized for storage and transmission.
- They are developer and IDE friendly, very easy to read and understand.
- They are easily or actually directly transformable from and to JavaScript objects.
- They are actually supported for most modern programming languages.
- They are API friendly.
Or in a few words, JSON specs means saving a lot of time and headaches.
Parametrized running
The same flow can be ran many times with different parameters provided from outside. Parameters can satisfy requirements for tasks that expect for them, in the same way they can be provided as output of another task. That also means, if you already have pre-calculated results, you can provide them to the flow and accelerate its execution.
Scoped visibility for tasks
All tasks in a flow, even the ones that have the same resolver, have a private space of names for parameters and results. That means:
- When developing a new resolver, the developer don’t have take care of name collisions.
- Resolvers are always reusable between flows.
But, what happends with resourses that I want to share all through the flow? Loggers, connections, application references, whatever. In that case, you can use a “context” that’s also available in all the flow tasks. All resources in the contexts are shared.
Run flows from string, object, file or URL
Flow can be ran from a specification provided from a JSON string, a JavaScript object, a JSON file or an accessible URL that serves the spec in JSON.
Pause/Resume and Stop/Reset functions
Flow executions can be paused and resumed with task granularity. The same for stopping and resetting, that last being to set the flow up to start from the beginning.
Inline parameters transformation
Task parameters can be transformed before running each task using an inline template.
In this example, given the current date new Date(), a simple flow is used to get a plane JavaScript object with day, month and year.
The template embedded in the flow is:
{
day: '{{date.getDate()}}',
month: '{{date.getMonth() + 1}}',
year: '{{date.getFullYear()}}'
}
Where date is known by the template because it is in the requires list of the task convertToObj.
const flow = {
tasks: {
getDate: {
provides: ['date'],
resolver: {
name: 'flowed::Echo',
params: { in: { value: new Date() } },
results: { out: 'date' },
}
},
convertToObj: {
requires: ['date'],
provides: ['result'],
resolver: {
name: 'flowed::Echo',
params: {
in: {
transform: {
day: '{{date.getDate()}}',
month: '{{date.getMonth() + 1}}',
year: '{{date.getFullYear()}}',
}
}
},
results: { out: 'result' },
}
}
},
};
FlowManager.run(flow, {}, ['result']);
The result got today (01/03/2020) is { day: 3, month: 1, year: 2020 }.
In order to use the benefits of the template transformation I highly recommend to take a look at the ST documentation and check the features and examples. Also play with this tool provided by ST, and design your templates dynamically.
Cyclic flows
Flows can have cyclic dependencies forming loops. In order to run these flows, external parameters must raise the first execution.
Timer example:
This resolver will check a context value to know if the clock must continue ticking or not.
Also the current tick number is output to the console.
class Print {
exec({ message }, context) {
return new Promise((resolve, reject) => {
let stop = false;
context.counter++;
if (context.counter === context.limit) {
stop = true;
}
setTimeout(() => {
console.log(message, context.counter);
resolve(stop ? {} : { continue: true });
}, 1000);
});
}
}
And the flow execution:
flowed.FlowManager.run({
tasks: {
tick: {
requires: ['continue'],
provides: ['continue'],
resolver: {
name: 'Print',
params: { message: { value: 'Tick' } },
results: { continue: 'continue' },
}
},
},
}, { continue: true }, [], { Print }, { counter: 0, limit: 5 },
);
The expected console output is:
Tick 1
Tick 2
Tick 3
Tick 4
Tick 5
Note that the task requires and provides the same value continue.
In order to solve the cyclic dependency and start running the flow, the first value for continue is provided in the parameters { continue: true }. Otherwise, the flow would never start.
The dependency loops can be formed by any number of tasks, not only by the same as in this simple example.
Library with reusable frequently used tasks
For several common tasks, resolvers are provided in the bundle, so you don’t have to worry about programming the same thing over and over again. You just have to take care of your custom code.
For more information, please check the Built-In resolver library documentation
Or go directly to the desired resolver details:
Plugin system
Using the Flowed plugin system, any developer can add their own resolver library and easily integrate it into the flow engine.
Custom resolver libraries can even be published and distributed as independent NPM packages.
Debugging
(debugging doc coming soon…)